

You just landed a new big, long term account. You need to develop a proper understanding of the industry, how it is structured, and who the leaders are so you can help your client develop strong relationships as well as establish strong thought leadership in the industry.
One way to find those people is through industry publications that feature leaders who contribute content on strategies and industry best practices.
In this tutorial, we will use crawling and scraping to create the nucleus of such a database - a list of influencers you could utilize. I will be using Python, and you can get an interactive version of the tutorial if you want to follow along, modify the code, or later use it as a template.
To make it familiar, the industry is the online marketing and advertising industry, the publication is the SEMrush blog, and the crawler is the open-source advertools crawler.
At the time of this writing, this blog has 393 authors, each with a profile page. You could manually copy and paste all their profiles and links, but your time is much more valuable than that.
Preparation (pages and data elements to extract)
The full list of bloggers with a link to each blogger's profile page can be found on a few pages with this template:
https://www.semrush.com/blog/authors/all/?page={n} — where "n" is a number ranging from one to fourteen.
We first start by generating a list of those pages. The crawler will be instructed to start here.
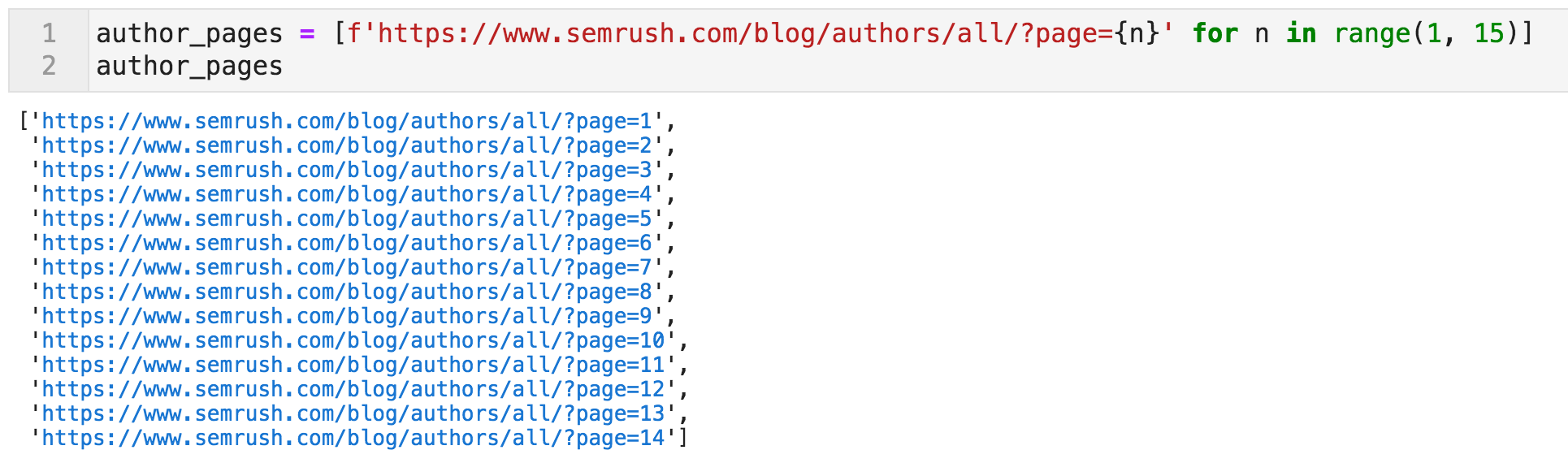 Code to create a list of URLs containing links to bloggers' profiles
Code to create a list of URLs containing links to bloggers' profiles
From these pages, the crawler should follow the links and from each profile page extract certain elements that we are interested in, using CSS selectors. If you are not familiar with CSS (or XPath) selectors, they are basically a way for you to specify parts of the page in a language that is more explicit and specific than "list items" for example, but also in a way that corresponds to how we think and view pages.
You most likely don't want all the links from a page. You typically want something like "all the links in the top part of the page that have social media icons".
I use a nice browser tool called SelectorGadget to help me find the names of the selectors. Once you activate it, any click you make on a part of the page gets highlighted in green, together with all similar elements. If you want to be more specific, you can click on other elements to deselect them.
In the example below, I first clicked on the LinkedIn icon, which also selected several other links on the page. Then once I clicked on the Home icon, it deselected all other elements (that is why it is now in red - see image below), and I am given the selector that corresponds to this specific element.
At the bottom of the page, you can see .b-social-links__item_ico_linkedin, which will unambiguously identify the LinkedIn links on these pages. You can also click on the XPath button to get the equivalent pattern if you want. So this is how we specify to the crawler which elements we want. Meet A.J., our all-time #1 champion!
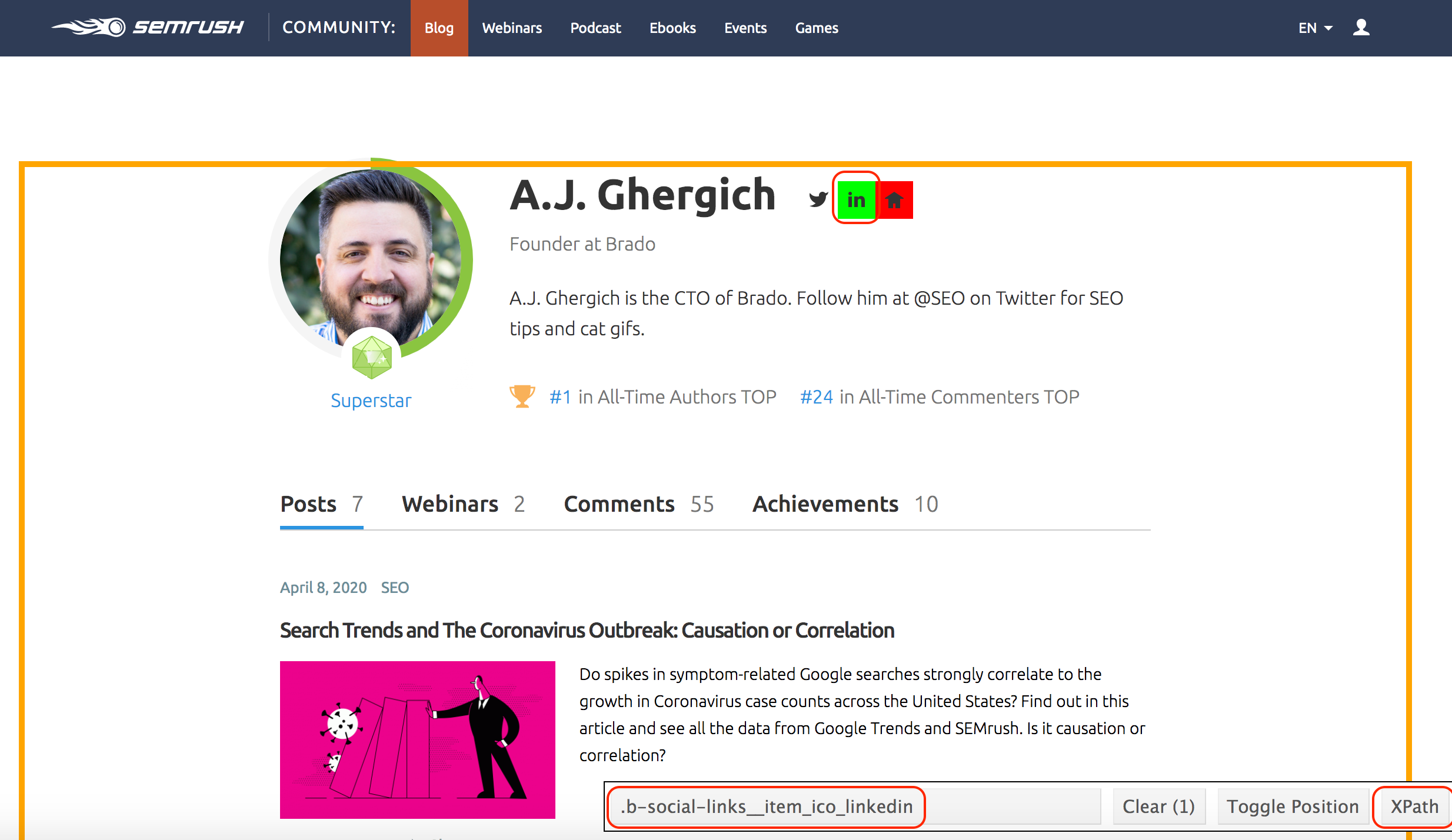 Using CSS and/or XPath selectors to extract page elements
Using CSS and/or XPath selectors to extract page elements
I did the same for other elements, and they are named below in this {key: value} mapping (Python dictionary).
The keys can be named whatever you want, and they will become the column names in the crawl output file. The values are what the crawler will extract. Note that the selectors end with ::text or ::attr(href). If you don't specify that, you will still get the links extracted correctly, but you will get the whole link object:
<a href="https://example.com>Link Text</a>. In each case, we specified whether we want the href or the text attribute.
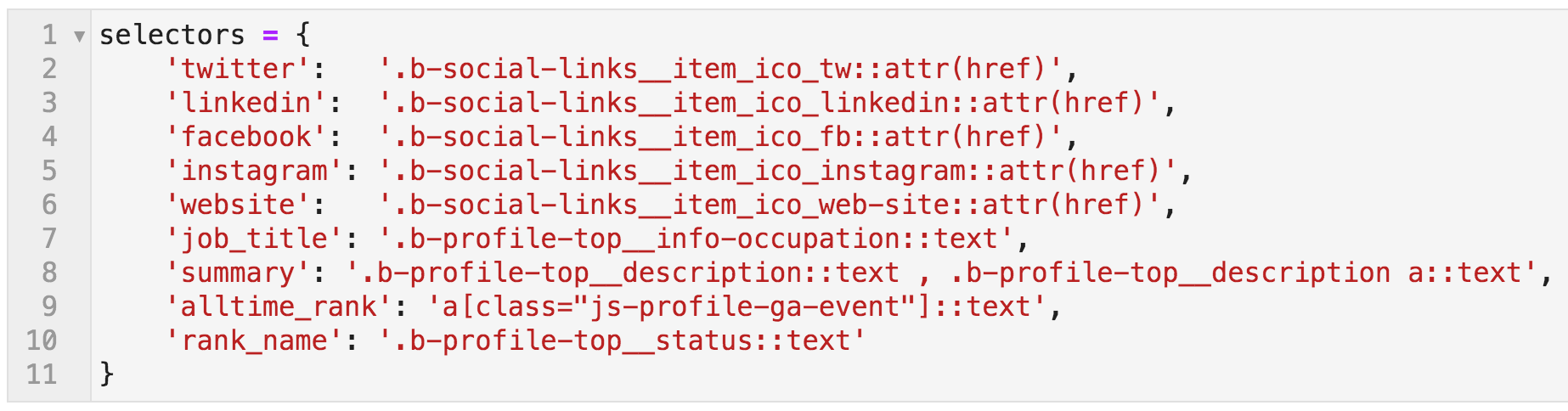 CSS selectors: names mapped to the extraction patterns
CSS selectors: names mapped to the extraction patterns
So now, we have the start pages ready, and we have the elements that we want to extract. To crawl, we use the command below:
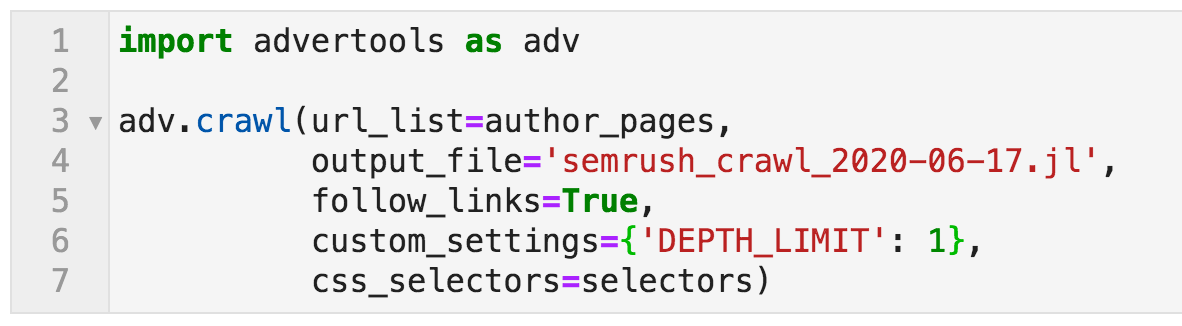 Crawl command specifying various options
Crawl command specifying various options
Let me explain:
import advertools as adv: activate the advertools package and use the alias adv to refer to it as a shorthand. crawl is the name of the function for crawling, and it takes a few parameters for customizing its behavior. url_list=author_pages: This is where the crawler will start crawling. author_pages is the name we gave to the list of the fourteen URLs that contain links to the bloggers' profiles. output_file: This is where we want the crawl data to be saved. It is always good to provide a descriptive name, together with the date. ".jl" is for "jsonlines", which is a flexible way of storing the data, where each URL's data will be saved in an independent line in the file. We will import it as a DataFrame, which can then be saved to CSV format for easier sharing. follow_links=True: If set to False, then the crawler would only crawl the specified pages, which is also known as "list mode". In this case, we want the crawler to follow links. What this means is that for every page crawled, all links will be followed. Now we don't want to crawl the whole website, so we use the following setting to limit our crawl. 'DEPTH_LIMIT': 1: Yes, do follow the links you find on the initial pages, and crawl the pages you find, but only one level after the initial fourteen. selectors: Refers to the dictionary we created to specify the data we want to be extracted.There are many different options for crawling, and you can check the documentation if you are interested in more details. This takes a few minutes, and now we can open the file using the pandas function read_json, and by specifying lines=True (because it's jsonlines).
 Command to open the crawl output file using pandas
Command to open the crawl output file using pandas
Now we have defined the variable semrush to refer to the crawl DataFrame. Let's first take a look at the columns it contains. As you can see below, there are eighty-three columns. The majority are fixed, meaning they will always be present in any crawl file (like "title", "h1", "meta_desc", etc.), and some are dynamic.
For example, OpenGraph data might exist on a page and might not, so some columns only appear if they are on the page. The columns that have social network names and the names we specified above would only appear if we explicitly specify them as we did in this example.
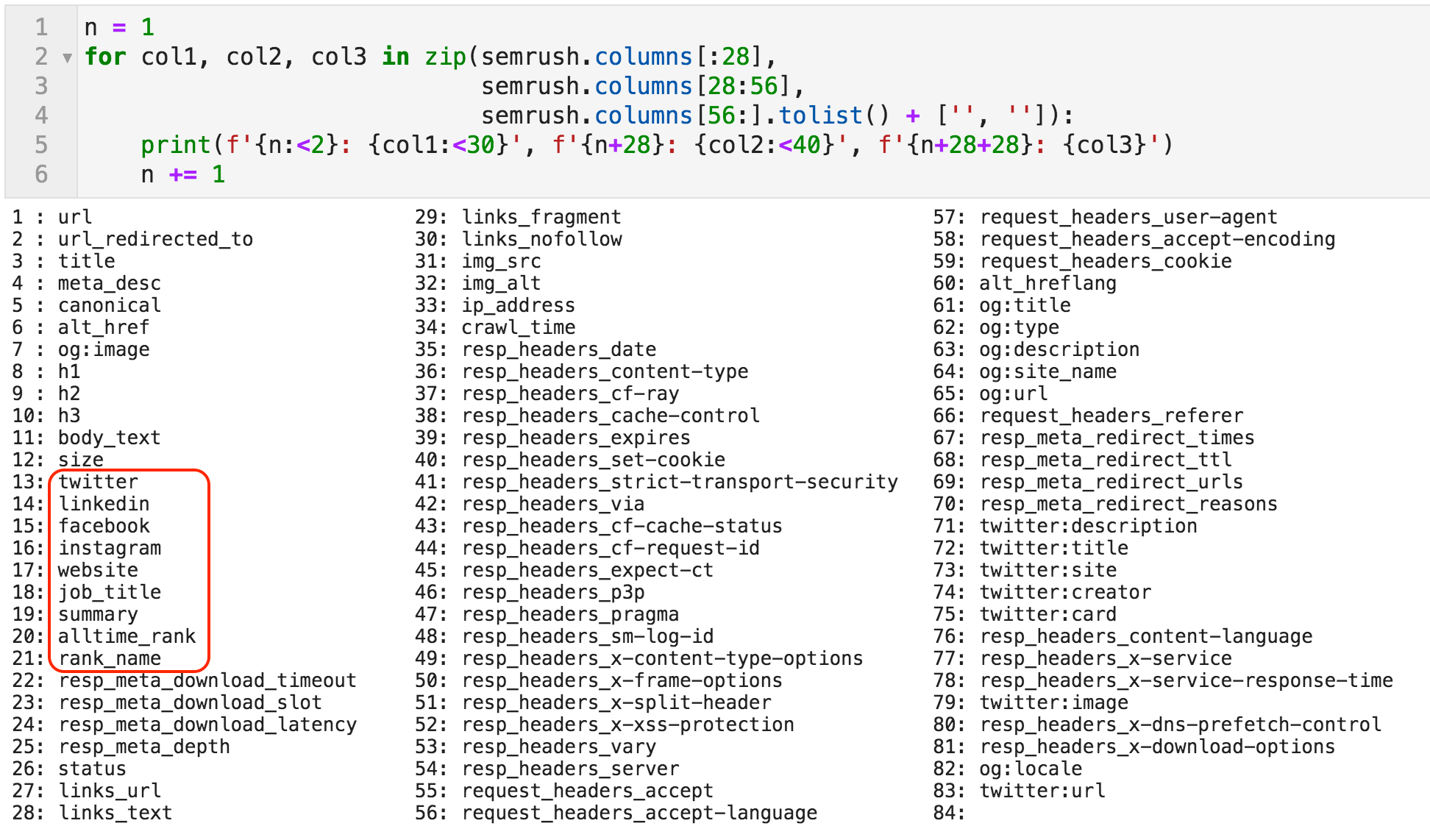 List of all the columns in the crawl file
List of all the columns in the crawl file
Since this is not an SEO audit, we are only interested in the extracted data related to the authors; we will now create a subset of the data. It basically says that we want the subset of semrush (called authors) where the cells of the column alltime_rank are not empty, and where the columns are "h1", "url", or any of the keys that we specified for extraction.
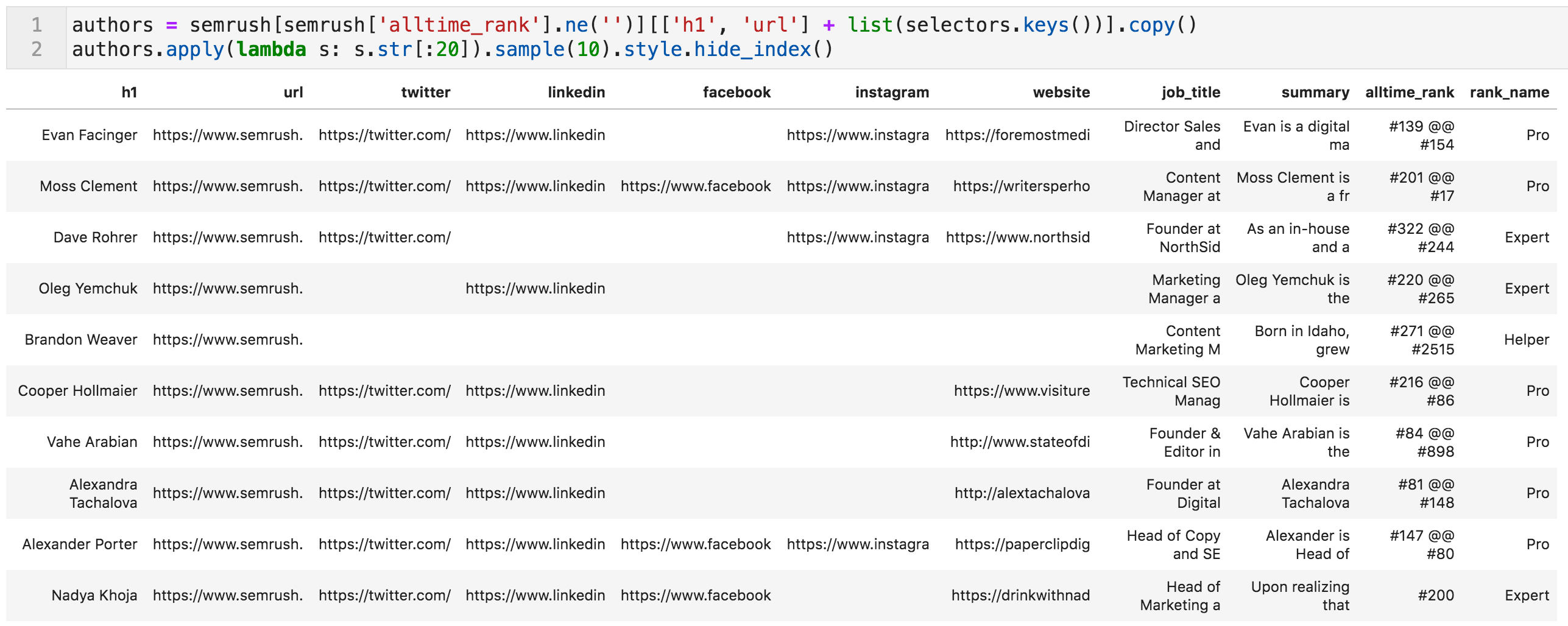 Random sample of the authors table (values truncated to fit on screen)
Random sample of the authors table (values truncated to fit on screen)
We are almost done. Some cleaning of the data is needed.
Cleaning Up the Data
You might have noticed the additional characters in the alltime_rank column, as well as the fact that it contains two values; one for the rank in posts, and another for the rank in comments. The following code splits the two values and removes the noisy characters.
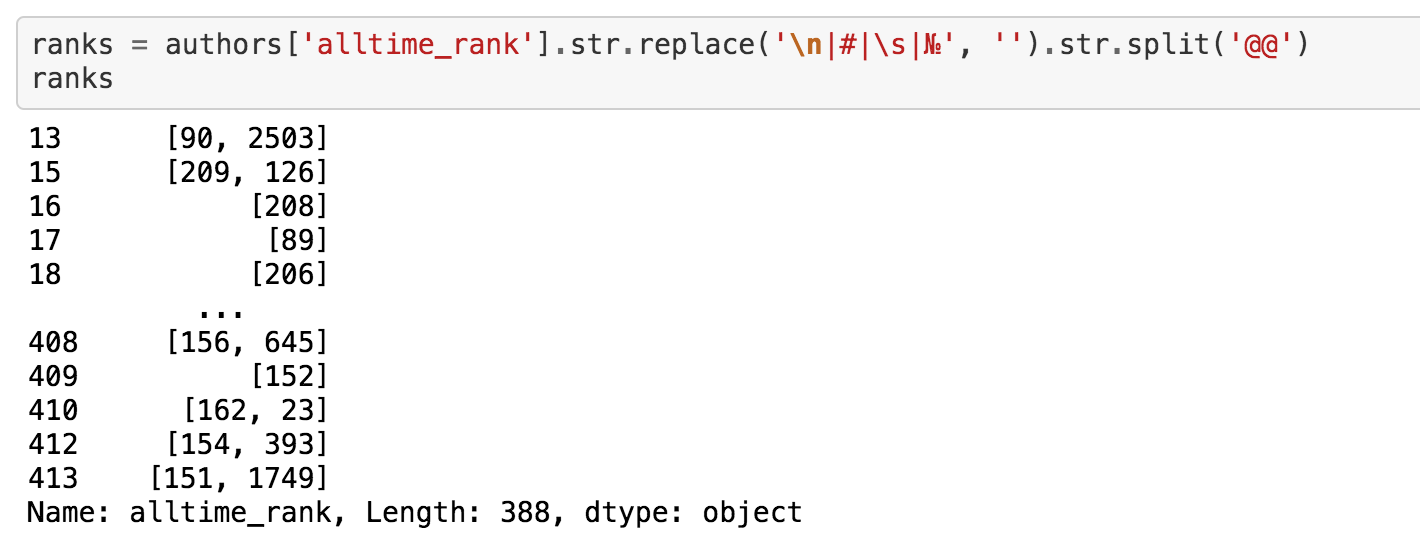 Code to remove unnecessary characters from "alltime_rank"
Code to remove unnecessary characters from "alltime_rank"
Now we can create two separate columns, one for each rank, and make sure they are integers so we can sort by those columns. In some cases where the blogger doesn't have a rank for comments, we give them a rank of zero.
 Code to create two new columns from "alltime_rank"
Code to create two new columns from "alltime_rank"
One final step. The columns job_title and rank_name contain some whitespace at the beginning and end, so we remove it. We also remove the delimiter appearing in the summary columns, which are two @ characters "@@".
This is because many summaries contain links in them, and they are extracted as three or four elements, so we remove the delimiter. Finally, we rename "h1" to "name", and "url" to "semrush_profile", sort by "alltime_rank_posts", and remove the column "alltime_rank".
And we are done!
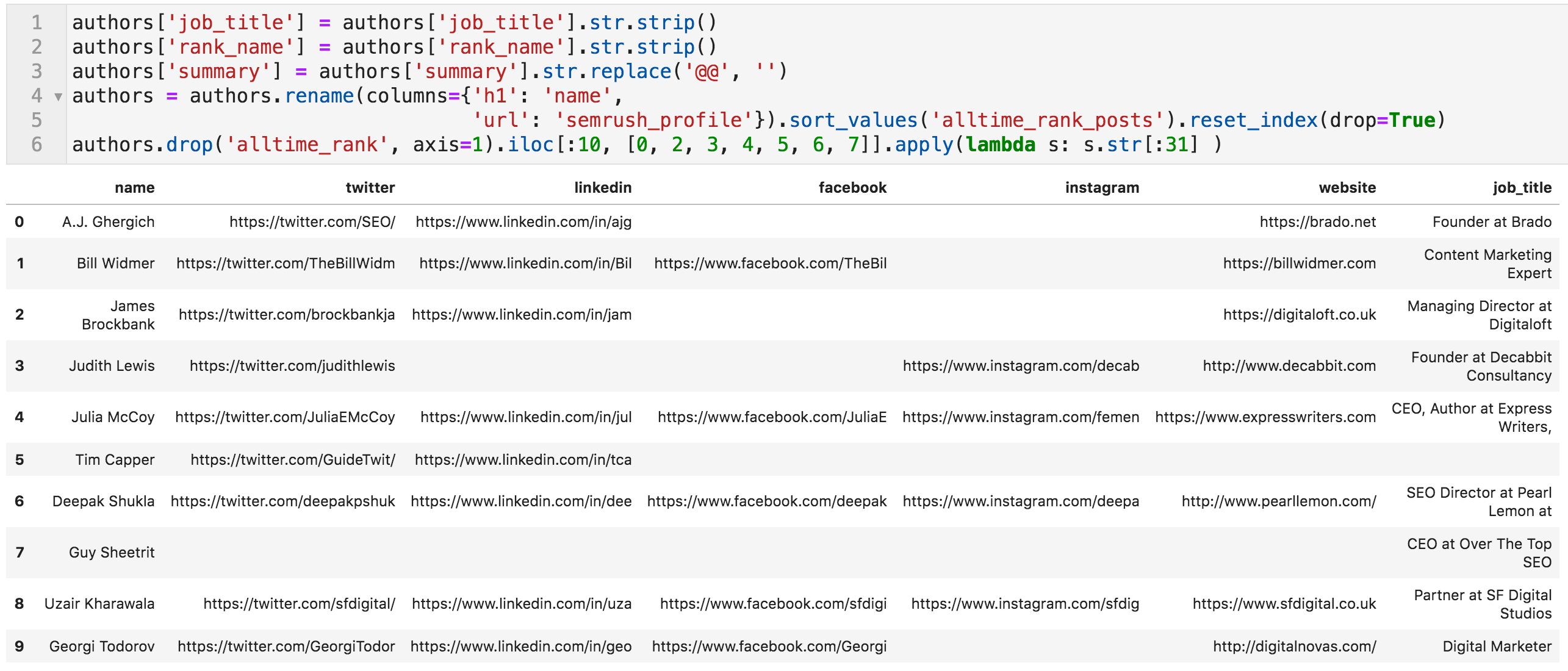 Code to make final edits, and the top ten bloggers (values truncated to fit on screen)
Code to make final edits, and the top ten bloggers (values truncated to fit on screen)
Let's quickly check if the work seems to be correct. Let's see how many rows and columns we have in authors:
 Get the shape (number of rows and columns) of the DataFrame
Get the shape (number of rows and columns) of the DataFrame
388 rows and 13 columns. Weren't they 393?
That is true. It seems there are five bloggers who have special profile pages that have the same data but in a different design (different CSS selectors). These are the "Columnists" of the blog. I have manually extracted their data and added them to the table, which you can see in the final semrush_blog_authors.csv file.
A very optimistic person once found a horseshoe on the floor and immediately thought, "Oh, now I only need three more horseshoes and a horse!"
This list is only one horseshoe.
The horse is the process of actually talking to those people, building real relationships, and finding a meaningful way to contribute to the network.
Now that you have a list of all the Twitter accounts, you might want to create a list to keep track of the people you find interesting. You might only be interested in a subset, so you can filter by the title or summary for profiles containing "content", "SEO", "paid", or whatever you are interested in.
The blog is published in several languages, so you could do the same for another language. With all the LinkedIn profiles, you might consider creating or joining a specialist group and inviting people to it.
Good luck!
Innovative SEO services
SEO is a patience game; no secret there. We`ll work with you to develop a Search strategy focused on producing increased traffic rankings in as early as 3-months.
A proven Allinclusive. SEO services for measuring, executing, and optimizing for Search Engine success. We say what we do and do what we say.
Our company as Semrush Agency Partner has designed a search engine optimization service that is both ethical and result-driven. We use the latest tools, strategies, and trends to help you move up in the search engines for the right keywords to get noticed by the right audience.
Today, you can schedule a Discovery call with us about your company needs.
Source:


