

Some content on your site is not necessary for search engines to index. To prevent indexing of necessary pages, you can use a robots meta tag or x-robots-tag.
However, it's not uncommon for robots.txt and robots meta tags to be used incorrectly. This results in messy and conflicting directives that don't achieve the result that's wanted: to prevent a page from being indexed.
And in this guide, we want to help you to understand how to use robots meta tags and the x-robots-tag to control the indexation of your website's content and to help you to spot commonly made mistakes.
Specifically, we're going to take a look at:
What Are Robots Meta Tags? Understanding Robots Meta Tag Attributes and Directives Meta Robots Tag Code Examples Using Meta Robots Tags to Control Snippets What Is the X‑Robots-Tag? How to Set Up Robots Meta Tags and X‑Robots-Tag Common Meta Robots MistakesWhat Are Robots Meta Tags?
A Robots meta tag, also known as robots tags, is a piece of HTML code that's placed in the <head></head> section of a web page and is used to control how search engines crawl and index the URL.
This is what a robots meta tag looks like in the source code of a page:
<meta name="robots" content="noindex" />These tags are page-specific and allow you to instruct search engines on how you want them to handle the page and whether or not to include it in the index.
What Are Robots Meta Tags Used For?
Robots meta tags are used to control how Google indexes your web page's content. This includes:
Whether or not to include a page in search results Whether or not to follow the links on a page (even if it is blocked from being indexed) Requests not to index the images on a page Requests not to show cached results of the web page on the SERPs Requests not to show a snippet (meta description) for the page on the SERPsIn order to understand how you can use the robots meta tag, we need to look at the different attributes and directives. We'll also share code examples that you can take and drop into your page's header to request the search engines to index your page in a certain way.
Understanding Robots Meta Tag Attributes and Directives
Using robots meta tags is quite simple once you understand how to set the two attributes: name and content. Both of these attributes are required, so you must set a value for each.
Let's take a look at these attributes in more detail.
Name
The name attribute controls that crawlers and bots (user-agents, also referred to as UA) should follow the instructions contained within the robots meta tag.
To instruct all crawlers to follow the instructions, use:
name="robots"
In most scenarios, you'll want to use this as default, but you can use as many different meta robots tags as needed to specify instructions to different crawlers.
When instructing different crawlers, it's simply a case of using multiple tags:
<meta name="googlebot" content="noindex"> <meta name="googlebot-news" content="nosnippet">There are hundreds of different user-agents. The most common ones are:
Google: Googlebot (you can see a full list of Google crawlers here) Bing: Bingbot (you can see a full list of Bing crawlers here) DuckDuckGo: DuckDuckBot Baidu: Baiduspider Yandex: YandexBotContent
The content attribute is what you use to give the instructions to the specified user-agent.
It's important to know that if you do not specify a meta robots tag on a web page, the default is to index the page and to follow all of the links (unless they have a rel="nofollow" attribute specified inline).
The different directives that you can use includes:
index (include the page in the index) [Note: you do not need to include this if noindex is not specified, it is assumed as index) noindex (do not include the page in the index or show on the SERPs) follow (follow the links on the page to discover other pages) nofollow (do not follow the links on the page) none (a shortcut to specify noindex, nofollow) all (a shortcut to specify index, follow) noimageindex (do not index the images on the page) noarchive (do not show a cached version of the page on the SERPs) nocache (this is the same as noarchive, but only for MSN) nositelinkssearchbox (do not show a search box for your site on the SERPs) nopagereadaloud (do not allow voice services to read your page aloud) notranslate (do not show translations of the page on the SERPs) unavailable_after (specify a time after which the page should not be indexed)You can see a full list of the directives that Google supports here and the ones that Bing supports here.
Meta Robots Tag Code Examples
If you're looking for meta robots tag examples that you can use to control how the search engines crawl and index your web pages, you can use the below that looks at the most common use scenarios:
Do not index the page but follow the links to other pages:
<meta name="robots" content="noindex, follow" />Do not index the page and do not follow the links to other pages:
<meta name="robots" content="none" />Index the page but do not follow the links to other pages:
<meta name="robots" content="nofollow" />Do not show a copy of the page cache on the SERPs:
<meta name="robots" content="noarchive" />Do not index the images on a page:
<meta name="robots" content="noimageindex" /Do not show the page on the SERPs after a specified date/time:
<meta name="robots" content="unavailable_after: Friday, 01-Jan-21 12:59:59 ET" />If needed, you can combine directives into a single tag, separating these with commas.
As an example, let's say you don't want any of the links on a page to be followed and also want to prevent the images from being indexed. Use:
<meta name="robots" content="nofollow, noimageindex" /Using Meta Robots Tags to Control Snippets
While meta robots tags are most commonly used to control whether or not a page is indexed and whether or not the links on that page are crawled by search engines, they can also be used to control snippets on the SERPs.
Introduced in September 2019, Google wrote that webmasters were able to use "a set of methods that allow more fine-grained configuration of the preview content shown for your pages."
These come in the form of the following meta robots tags:
nosnippet (do not show a snippet/meta description for the page on the SERPs) max-snippet:[number] (specify the maximum text length of a snippet in characters) max-video-preview:[number] (specify the maximum duration of a video preview in seconds) max-image-preview:[setting] (specify the maximum size of an image preview either as "none," "standard," or "large")Use the following code to control how your web page's snippets are displayed:
Do not show snippets for a page on the SERPs:
<meta name="robots" content="nosnippet" />Set the maximum length of a text snippet to 150 characters:
<meta name="robots" content="max-snippet:150" />Set the maximum duration of a video preview to 20 seconds:
<meta name="robots" content="max-video-preview:30" />Set the maximum size of an image preview to large:
<meta name="robots" content="max-image-preview:large" />These can also be combined to give greater control over your page's snippets. Let's say you want to set the maximum length of your snippet to 150 characters and allow large image previews, use:
<meta name="robots" content="max-snippet:150, max-image-preview:large" />If you have an audience in France, you need to pay close attention to these tags as French copyright law prevents Google from showing any snippets at all for your website unless you opt-in using these.
If you do not want to place any restrictions on your snippets, you can add the below sitewide in your page header:
<meta name="robots" content="max-snippet:-1, max-image-preview:large, max-video-preview:-1" />What Is the X‑Robots-Tag?
An alternative way to control how search engines crawl and index your webpages is to use the x-robots-tag rather than meta robots tags.
While implementing meta robots tags to HTML pages is relatively straightforward, x-robots-tag is more complicated. If you want to control how non-HTML content is handled, for example, a PDF, you'll need to use the x-robots-tag.
This is an HTTP header response, rather than an HTML tag, and any directive that can be used as a meta robots tag can also be used as an x-robots-tag.
Here's an example of what an x-robots-tag header response looks like:
x-robots-tag: noindex, nofollowIn order to use the x-robots-tag, you'll need to be able to access your site's website’s header .php, .htaccess, or server configuration file. If you do not have access to this, you will need to use meta robots tags to instruct crawlers.
When to Use the X‑Robots-Tag?
Using an x-robots-tag is not as straightforward as using meta robots tags, but allows you to direct search engines how to index and crawl other file types.
Use the x-robots-tag when:
You need to control how search engines crawl and index non-HTML file types You need to serve directives at global level (sitewide) rather than at page-levelHow to Set Up Robots Meta Tags and X‑Robots-Tag
Setting up robots meta tags is, generally, easier than the x-robots-tag, but the implementation of both methods of controlling how search engines crawl and index your site can differ depending on your CMS and/or server type.
Here's how yo use meta robots tags and the x-robots-tag on common setups:
Using Robots Meta Tags in HTML Code Using Robots Meta Tags on WordPress Using Robots Meta Tags on Shopify Using X-Robots-Tag on an Apache Server Using X-Robots-Tag on an Nginx ServerUsing Robots Meta Tags in HTML Code
If you can edit your page's HTML code, simply add your robots meta tags straight into the <head> section of the page.
If you want search engines not to index the page but want links to be followed, as an example, use:
<meta name="robots" content="noindex, follow" />Using Robots Meta Tags on WordPress
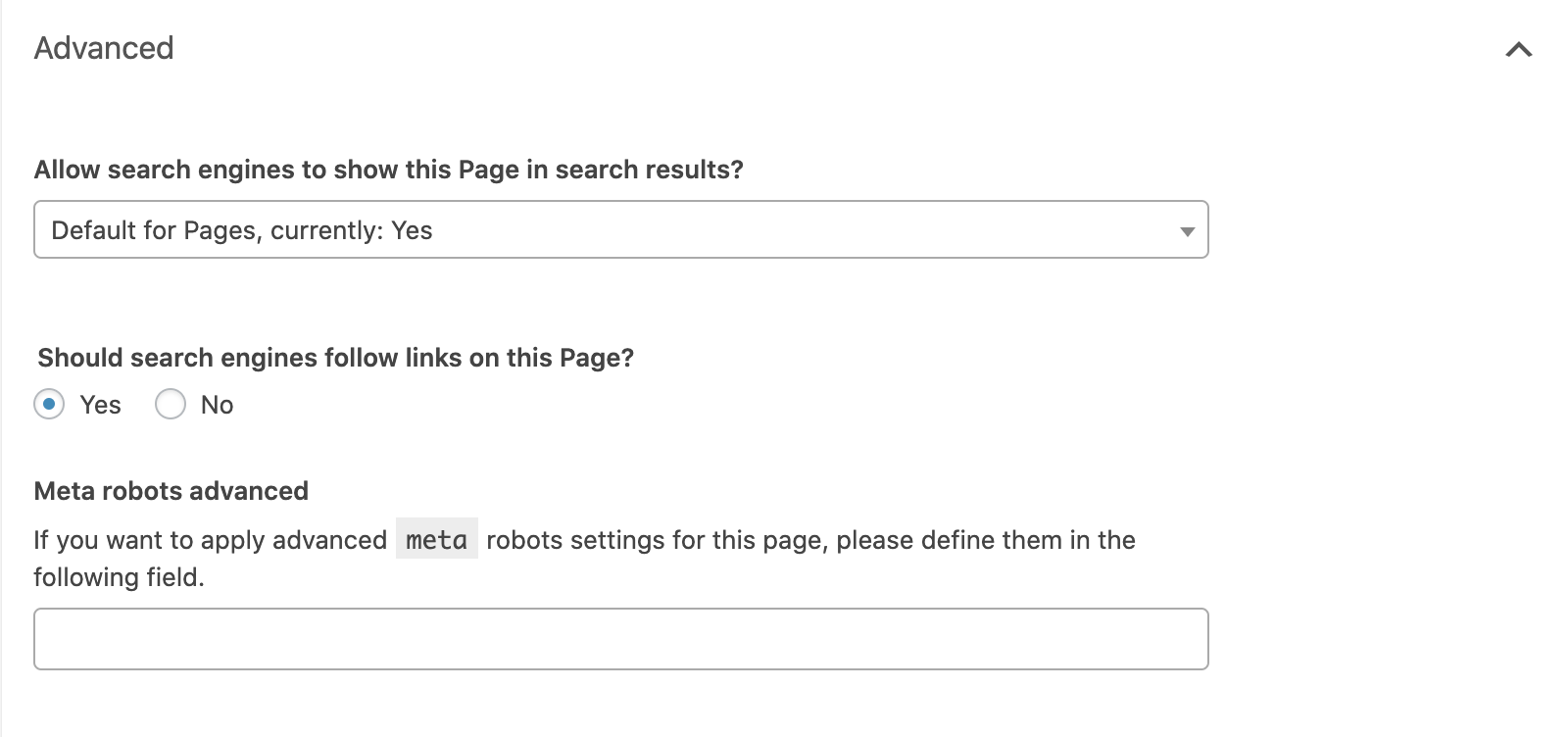
If you're using Yoast SEO, open up the 'advanced' tab in the block below the page editor.
You can set the "noindex" directive by setting the "Allow search engines to show this page in search results?" dropdown to no or prevent links from being followed by setting the "Should search engines follow links on this page?" to no.
For any other directives, you will need to implement these in the "Meta robots advanced" field.
If you're using RankMath, you can select the robots directives that you wish apply straight from the Advanced tag of the meta box:
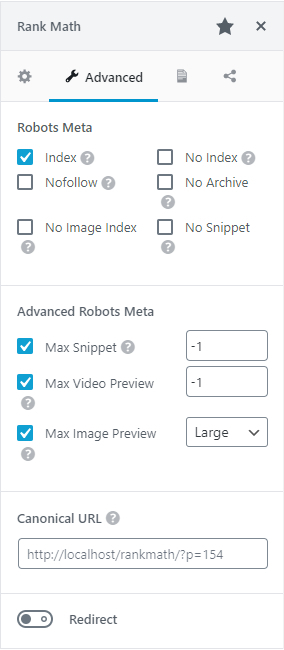 Image courtesy of RankMath
Image courtesy of RankMath
Using Robots Meta Tags on Shopify
If you need to implement robots meta tags on Shopify, you'll need to do this by editing the <head> section of your theme.liquid layout file.
To set the directives for a specific page, add the below code to this file:
{% if handle contains 'page-name' %} <meta name="robots" content="noindex, follow"> {% endif %}This code will instruct search engines, not to index /page-name/ but to follow all of the links on the page.
You will need to make separate entries to set the directives across different pages.
Using X-Robots-Tag on an Apache Server
To use the x-robots-tag on an Apache web server, add the following to your site's .htaccess file or httpd.config file.
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, follow" </Files>The example above sets the file type of .pdf and instructs search engines not to index the file but to follow any links on it.
Using X-Robots-Tag on an Nginx Server
If you're running an Nginx server, add the below to your site's .conf file:
location ~* \.pdf$ { add_header X-Robots-Tag "noindex, follow"; }This will apply a noindex attribute and follow any links on a .pdf file.
Common Meta Robots Mistakes
It's not uncommon for mistakes to be made when instructing search engines how to crawl and index a web page, with the most common being:
Meta Robots Directives on a Page Blocked By Robots.txt Adding Robots Directives to the Robots.txt File Removing Pages With a Noindex Directive From Sitemaps Accidentally Blocking Search Engines From Crawling an Entire SiteMeta Robots Directives on a Page Blocked By Robots.txt
If a page is disallowed in your robots.txt file, search engine bots will be unable to crawl the page and take note of any directives that are placed in meta robots tags or in an x-robots-tag.
Make sure that any pages that are instructing user-agents in this way can be crawled.
If a page has never been indexed, a robots.txt disallow rule should be sufficient to prevent this from showing in search results, but it is still recommended that a meta robots tag is added.
Adding Robots Directives to the Robots.txt File
While never officially supported by Google, it used to be possible to add a noindex directive to your site's robots.txt file and for this to take effect.
This is no longer the case and was confirmed to no longer be effective by Google in 2019.
Removing Pages With a Noindex Directive From Sitemaps
If you are trying to remove a page from the index using a noindex directive, leave the page in your site's sitemap until this has happened.
Removing the page before it has been deindexed can cause delays in this happening.
Accidentally Blocking Search Engines From Crawling an Entire Site
Sadly, it's not uncommon for robots directives that are used in a staging environment to accidentally be left in place when the site moves to a live server, and the results can be disastrous.
Before moving any site from a staging platform to a live environment, double-check that any robots directives that are in place are correct.
You can use the Semrush Site Audit Tool before migrating to a live platform to find any pages that are being blocked either with meta robots tags or the x-robots-tag.
Innovative SEO services
SEO is a patience game; no secret there. We`ll work with you to develop a Search strategy focused on producing increased traffic rankings in as early as 3-months.
A proven Allinclusive. SEO services for measuring, executing, and optimizing for Search Engine success. We say what we do and do what we say.
Our company as Semrush Agency Partner has designed a search engine optimization service that is both ethical and result-driven. We use the latest tools, strategies, and trends to help you move up in the search engines for the right keywords to get noticed by the right audience.
Today, you can schedule a Discovery call with us about your company needs.
Source:


